

*UPDATE: I’ve switched over to Hugo for my CV site. The example used in this and following posts will still work for your Jekyll sites, but if you have a Hugo site, take a look here:
I run my own gitea instance and I’m slowly moving all of my code (compose files, dotfiles, websites…) into it. I’ve never been a huge user of git at home, but you can’t argue with being able to track changes in all of your config!
Since I have all of this great data in a repo, I should be able to trigger things off changes. I work quite a bit with organisations transforming to use devops and infrastructure as code. I really need to do this at home too!
In this post, I’ll talk a little about how I went about assessing each of the candidade CICD platformas as well as go through the implementation of each at a high level. I plan to write another post on each of the candidates talking about how to create their pipelines and how they run.
My Requirements
- Docker! - I run my entire self hosted setup on ubuntu servers with docker. I find docker the easiest way to get services up and running, and to back them up. It’s also quite mobile if I ever need to rebuild. The CICD platform needs to be able to run in docker and also to utilise docker for tasks in the pipeline steps (this is important as it means I don’t have to mess around installing things to make a pipeline step work)
- Single User - Only I will be using the stack for my own self hosted network so I wan’t looking to closely into user collaboration / scaling
- Integrates with Gitea - There has to be a way to trigger pipelines from gitea
- Lightweight - I’m not running server grade hardware at home. Power bills, noise, heat and space preclude setting up a rack. I have a bunch of small form factor machines dotted around the house. This means I try not tu use apps that require a huge amount of CPU and memory
- Easy to Maintain - Nobody has time to keep tinkering with getting software to work. We just and to tinker with what it can do!
- Secure - I would like to minimize the attak surface that the platform exposes. This means things like plugins and hacks should be minimized
- Active - The platform should be actively being developed. This is to flush out bugs ad add sexy new features
- Declarative Pipelines - This makes more sense in my head. Instead of defining steps to execute (imperative pipelines) I want to just define the desired state and let the platform take care of the rest.
- Open Source - I love open source software. I fint the FOSS community can build better and faster in most cases
My Shortlist
After doing some research on what people were using thin their home labs I came up with these three candidates:
- Jenkins - The old man of CICD. I believe this was the first CICD platform developed and has alot of years of development and use behind it
- ConcourseCI - Has been around since 2012 and has some backing from VMWare
- WoodpeckerCI - a fork of DroneCI after it went from open source to open-core Spoiler - I’m currently running WoodpeckerCI and it’s going well!
How I’m Testing
I’ve implemented each of the candidates and have tested them out by auto-deploying my personal landing page at https://cv.omaramin.me. This is a simple Jekyll site that’s residing in an nginx container. At a high level, on trigger of a git push to my site’s repository, the CICD pipeline should:
Step 1
Pull the Jekyll site code from github
Step 2
Pull the Jekyll builder docker image and build the site
Step 3
Build this Dockerfile and push the image to my gitea container repository
FROM nginx:alpine
COPY default /etc/nginx/sites-available/default
COPY _site /usr/share/nginx/html
COPY pdf/omaraminCV.pdf /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
Step 4
Pull the newly created docker image and restart the nginx container
How My Code is Structured
In terms of the project structure, I keep the dockerfile as well as the pipeline files for CICD in the same repository as the Jekyll site files:
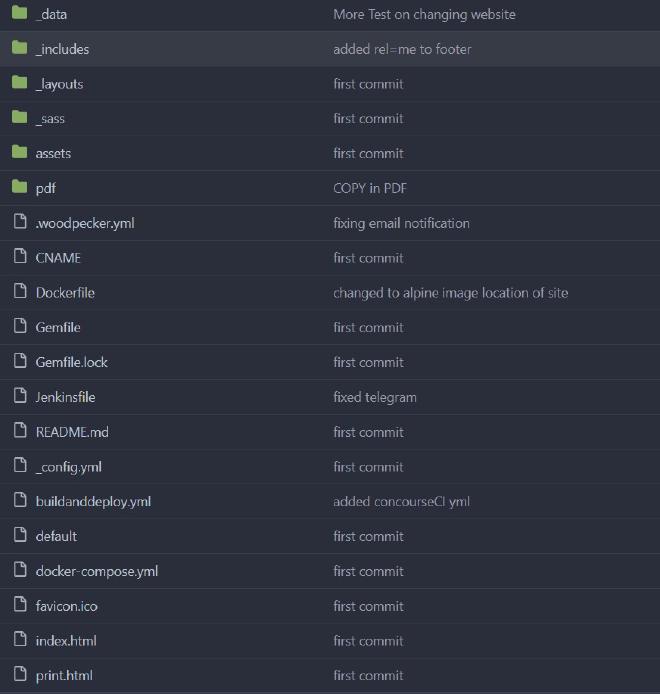
Jenkins
My first stop was Jenkins. This has been around for so long that it was pretty easy to find examples of people doing exactly the same thing I was doing. But oh boy were there alot of different approaches.
Installation
Installation was relatively simple. I used the default install instructions and ended up with the following docker compose block:
jenkins:
image: jenkins/jenkins:lts
container_name: jenkins
privileged: true
user: root
environment:
- TZ=$TZ
ports:
- 8080:8080
- 50000:50000
container_name: jenkins
volumes:
- $DOCKERPATH/jenkins/data:/var/jenkins_home
- /var/run/docker.sock:/var/run/docker.sock
After setting up jenkins fully, to integrate with Gitea, I had to install a plugin (more on that later) and I was up and running with the basics.
What’s interesting is that with this set up, we are still not ready to run pipelines. The way I want things to work is that docker containers are spun up automatically to run tasks. In order to do this with Jenkins, I need to configure my docker server as a cloud node and within it, an agent that “understands” docker commands (docker pull, run, etc…). This means running a “Docker In Docker” agent. This agent will basically instruct the docker daemon on my server to create, run and destroy containers as required.
An alternative to docker in docker (DinD) is to compile my own jenkins container to include containerd and docker. That seemed like a bit too much hassle to keep track of so I went for the DNID route. To set up DNID, you need to go into Manage Jenkins from the main page of your install and then Configure Clouds. I used someone else’s container as my DNID container: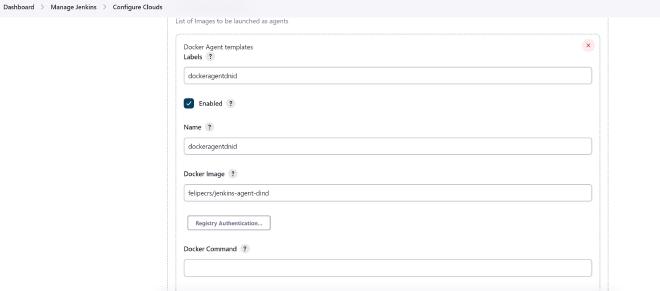
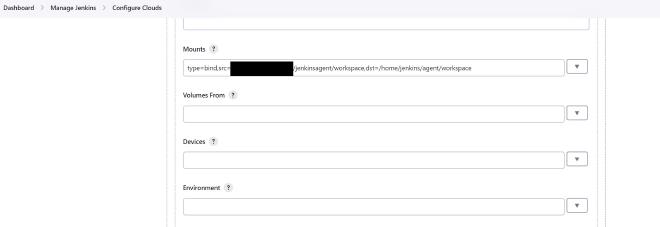
How we use the agent will become clearer in the post on Jenkinsfile structure:
The Good
- It was pretty easy to get up an running with the basics. I did have to bang my head against DinD for more hours than I care to mention, but that might just be because I’m learning the concepts from scratch.
- There’s a standard secrets plugin which is handy. I hard coded everything in my jenkinsfile as I was testing the pipeline and moved on before I got around to implementing the secrets
- There is a plugin for everything. Want to use Vault, there’s a plugin, want to be notified via Telegram, plugin… This is also a problem
- You can do almost anything in a jenkins pipeline… This is also a problem
- There’s a hell of alot of experience and knowledge out there already that you can easily find with a web search
- Decent integration into Gitea. I can see the build status for each of my commits
The Bad
- There are no guard rails. You can do some pretty silly things in pipelines and you’re the only one to blame
- Everything is dependent on plugins, alot of which are unmaintained. That’s alot of trust to place into different code
- I found the Jenkinsfile syntax to be quite a learning curve
- Pipeline error messages were quite obtuse at times. I had to spend alot of time searching forums to figure out what my pipeline issues were
- From what I’ve read online, updates to jenkins quite often cause plugins to break. Since Jenkins is so dependent on plugins, this causes your pipelines to break
ConcourseCI
Concourse is an interesting one. It’s very agnostic to the code repository (although I believe it does have integration with github) and is “docker native” in that you don’t need any special configuration to get it up and running while utilising container agents.
Installation
Installation was also pretty simple. I was up and running by following this guide with the following compose blocks:
concourse:
image: concourse/concourse
command: quickstart
privileged: true
depends_on: [concourse-db]
ports: ["8081:8080"]
environment:
CONCOURSE_POSTGRES_HOST: concourse-db
CONCOURSE_POSTGRES_USER: concourse
CONCOURSE_POSTGRES_PASSWORD: <DB_PASS>
CONCOURSE_POSTGRES_DATABASE: concoursedb
CONCOURSE_EXTERNAL_URL: <URL>
CONCOURSE_ADD_LOCAL_USER: <USERNAME>:<USER_PASS>
CONCOURSE_MAIN_TEAM_LOCAL_USER: <USERNAME>
# instead of relying on the default "detect"
CONCOURSE_WORKER_BAGGAGECLAIM_DRIVER: overlay
CONCOURSE_CLIENT_SECRET: <SECRET>
CONCOURSE_TSA_CLIENT_SECRET: <SECRET>
CONCOURSE_X_FRAME_OPTIONS: allow
CONCOURSE_CONTENT_SECURITY_POLICY: "*"
CONCOURSE_CLUSTER_NAME: <NAME>
CONCOURSE_WORKER_CONTAINERD_DNS_SERVER: "<DNS_IP>"
CONCOURSE_WORKER_RUNTIME: "containerd"
concourse-db:
image: postgres
environment:
POSTGRES_DB: concoursedb
POSTGRES_PASSWORD: <DB_PASS>
POSTGRES_USER: concourse
PGDATA: /database
In addition to getting the containers up and running, you will need to install Fly. This is a command line tool that you use to set up pipeline and control Concourse. The pipelines are structured in YAML files that I keep with the rest of my site code. The one annoyance I had was setting up webhooks from Gitea. Getting the webhook syntax seems to be a bit sloppy
The Good
- Really easy to get up and running
- Pipeline syntax is pretty intuative
- The web interface is lightweight and does everything you need it to. It also has a really nice way of graphing your pipelines
- They’ve just released support for using Vault as a credential manager
- Flowing files from your git repo through multiple steps of a pipeline is seamless
The Bad
- Using Fly to set up the pipelines is a bit of a learning curve
For a deeper dive into ConcourseCI and it’s pipeline syntax, take a look at my post:
WoodpeckerCI
Forked from DroneCI when it went open-core. Drone is used by alot of people and enterprises so it’s tried and tested. From what I can tell, WoodpeckerCI is pretty compatible with drone configs. Pipeline syntax is YAML and I can keep the .woodpecker.yml file in the same repo as the rest of my site code.
Installation
Aslo very easy following these instructions. The install is made up of a server and any number of agents that communicate back to the server. This is the compose block that got me up and running:
woodpecker-server:
image: woodpeckerci/woodpecker-server:latest
ports:
- 8000:8000
volumes:
- $DOCKERPATH/woodpecker/data:/var/lib/woodpecker/
environment:
- WOODPECKER_OPEN=false
- WOODPECKER_ADMIN=<USERNAME>
- WOODPECKER_ORGS=<REPO_ORGANISATION>
- WOODPECKER_AUTHENTICATE_PUBLIC_REPOS=true
- WOODPECKER_HOST=<WOODPECKER_URL>
- WOODPECKER_GITEA=true
- WOODPECKER_GITEA_URL=<GITEA_URL>
- WOODPECKER_GITEA_CLIENT=<GITEA_CLIENT_ID>
- WOODPECKER_GITEA_SECRET=<GITEA_SECRET>
- WOODPECKER_AGENT_SECRET=<GITEA_AGENT_SECRET>
woodpecker-agent:
image: woodpeckerci/woodpecker-agent:latest
command: agent
restart: always
depends_on:
- woodpecker-server
volumes:
- /var/run/docker.sock:/var/run/docker.sock
environment:
- WOODPECKER_SERVER=woodpecker-server:9000
- WOODPECKER_AGENT_SECRET=<GITEA_AGENT_SECRET>
What’s really nice is that there’s no seperate user management. WoodpeckerCI uses the user database from Gitea and you can configure those users with different permissions.
The Good
- Tight integration with Gitea (also other repositories)
- Really easy pipeline syntax. The most intuative of the three
- Also “docker native”
- Web interface is lightweight and provides everything you need
- Built in credentials management
The Bad
- I haven’t found a way to set up global credentials so there’s a bit more initial setup of pipelines
For a deeper dive into WoodpeckerCI and it’s pipeline syntax, take a look at my post here:
Conclusion
I’m really liking WoodpeckerCI for the moment and both https://omaramin.me and https://cv.omaramin.me are built using WoodpeckerCI pipelines. I have noted that the trend seems to be for code repositories to start implementing CI functionality (e.g. github and gitlab have Actions and Gitea is even working on doing something similer). I haven’t decided if that’s a good thing though. It means a more complicated migration if I ever need to ditch Gitea (so much so that I have read that some people won’t move off Gitlab because migrating all of their Actions would be too much of a headache).